![[Python] YOLO 모델 학습을 위한 오픈 데이터 셋 준비 (2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FAZ20v%2Fbtsrq8cBLXJ%2F7PCYrQzB9DnVb2UUtl9Zk1%2Fimg.jpg)
이전 포스팅
[Python] YOLO 모델 학습을 위한 오픈 데이터 셋 준비 (1)
[Python] YOLO 모델 학습을 위한 오픈 데이터 셋 준비 (1)
=============== 목표 =============== YOLO 모델 학습을 위한 오픈 데이터셋 준비 ================================== 1. roboflow를 통해 배포되어 있는 오픈 이미지 데이터 셋 다운 2. 구글 OpenImageDataset과 Google BigQuery
coding-gym.tistory.com
《 OIDv4_ToolKit 활용 》
GitHub - EscVM/OIDv4_ToolKit: Download and visualize single or multiple classes from the huge Open Images v4 dataset
Download and visualize single or multiple classes from the huge Open Images v4 dataset - GitHub - EscVM/OIDv4_ToolKit: Download and visualize single or multiple classes from the huge Open Images v4...
github.com
설명에 의하면 약 600개 클래스를
포함한 이미지 데이터 셋을 다운로드 할 수 있다고 하네요.
기본적인 프로세스를 보면 Google Open Images Dataset V4에
기반해 원하는 특정 데이터 셋을 추출하는 것 같습니다.
우선 해당 GitHub를 본인의 프로젝트 위치에 clone합니다.
git clone https://github.com/EscVM/OIDv4_ToolKit.git
pip install -r requirements.txt

Git clone과 필요 패키지 들을 pip install을 통해 다운로드 받은 후
동일하게 Google Open Images Dataset V4에서 제공하는
클래스 파일을 확인 후 본인에게 해당 하는 이미지 클래스를 탐색합니다.
이제 본격적으로 이미지 데이터셋을 다운로드 받겠습니다.
--type_csv 파라미터를 통해 train 파일 test 파일 val 파일
혹은 전체 파일을 간단하게 다운로드 받을 수 있습니다.
| 명령어 | 설명 | 예시 |
| <command> | 'downloader' 'visualizer' 'ill_downloader' | downloader |
| 하이퍼 파라미터 | 설명 | 예시 |
| --classes | list of classes | Jellyfish |
| --type_csv | 'train' 'test' 'validation' 'all' | test |
| --sub | Subset of human verified images or machine generated h or m | h |
| --image_IsOccluded, --image_IsTruncated --image_IsGroupOf --image_IsDepiction --image_IsInside |
1 or 0 | |
| --multiclasses | default or 1 | 0 [default] |
| --n_threads | default 20 | |
| --noLabels | no labels | |
| --iimit | integer number | 20 |
# OIDv4_TooKit 폴더 경로로 이동
cd OIDv4_ToolKit
# main.py 실행
python main.py downloader --classes Jellyfish --type_csv test
해파리의 테스트 이미지 데이터셋 파일을 다운로드 받아보니 103개입니다.
정상적으로 해당 클래스의 테스트 이미지 파일과 label 파일을
다운로드 받은 것을 확인할 수 있습니다.
이 때 라벨 파일의 경우 정규화 되어 있지 않으므로
따로 yolo 형식의 라벨 데이터로 정규화 시켜야 합니다.


해당 정규화 코드는 아래 깃허브의 코드를 참조했습니다.
https://gist.github.com/EscVM/b6e5d60343c88f358742aa9e0de2cc3f
Translate OIDv4 labels to YOLO format
Translate OIDv4 labels to YOLO format. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
해당 코드를 작성한 파일을 임의로 oid_to_yolo.py로 변경하여
OIDv4_ToolKit 폴더 하위에서 실행해 줍니다.
# ---------------
# Date: 7/25/2018
# Place: Biella
# Author: EscVM
# Project: OID v4 to Yolo
# ---------------
import os
from tqdm import tqdm
from sys import exit
import argparse
import cv2
from textwrap import dedent
ROOT_DIR = 'OID' # 루트 폴더 경로 설정
OUTPUT_DIR = 'OUTPUT' # OUTPUT 경로 폴더명 설정
NAME_DIR = 'To_Yolo' # OUTPUT 경로 하위 폴더명 설정
def argument_parser():
parser = argparse.ArgumentParser(description='Convert OID format to Yolo')
parser.add_argument("command",
metavar="<command> 'convert' or 'dummy'",
help="'convert oid format to yolo' or 'dummy', add no target images")
parser.add_argument('--dataset', required=True,
metavar="type of dataset: 'validation', 'test', 'train', 'all'",
help='"validation" or "train" or "test" or "all"')
parser.add_argument('--class_name', required=True,
metavar="name of the class to convert",
help='Convert: name of the class Ex: "Apple" Dummy: where to add images')
parser.add_argument('--class_number', required=False,
default=0,
metavar="dictionary value of the class",
help="It's the value assigned to the class")
parser.add_argument('--copy', required=False,
default=False,
metavar="boolean: copy images in a common folder",
help="copy images with labels in a common folder")
parser.add_argument('--names', required=False,
default=False,
metavar="boolean: create .names file with classes",
help="boolean: create .names file with classes")
parser.add_argument('--dummy_name', required=False,
default=False,
metavar="class_name to add as dummy to class_name",
help="add images to class_name with void labels")
parser.add_argument('--move', required=False,
default=False,
metavar="boolean: move images from original folder",
help="if '1' moves imase to To_YOLO folder")
args = parser.parse_args()
return args
class Engine(object):
global ROOT_DIR
global OUTPUT_DIR
global NAME_DIR
def __init__(self, dataset, class_name, class_number, copy, names, move):
self.dataset = dataset
self.class_name = class_name
self.class_number = class_number
self.copy = copy
self.names = names
self.move = move
self.class_list = []
def run_converter(self):
self.make_start()
if self.dataset != 'all':
self.dataset_dir = os.path.join(ROOT_DIR, 'Dataset', self.dataset, self.class_name)
self.label_dir = os.path.join(self.dataset_dir, 'Label')
self.output_dataset_dir = os.path.join(OUTPUT_DIR, NAME_DIR, self.dataset, self.class_name)
if not os.path.exists(self.output_dataset_dir):
os.makedirs(self.output_dataset_dir)
self.img_file = os.listdir(self.dataset_dir)
print("[INFO] {} images found".format(len(self.img_file) - 1))
print("[INFO] ---- x | y | width | height ---- output format".format(len(self.img_file) - 1))
self.make_labels()
if self.names == '1':
self.make_names()
else:
dataset_DIR = os.path.join(ROOT_DIR, 'Dataset')
dataset_list = tuple(os.listdir(dataset_DIR))
for dataset in dataset_list:
self.dataset_dir = os.path.join(ROOT_DIR, 'Dataset', dataset, self.class_name)
self.label_dir = os.path.join(self.dataset_dir, 'Label')
self.output_dataset_dir = os.path.join(OUTPUT_DIR, NAME_DIR, dataset, self.class_name)
if not os.path.exists(self.output_dataset_dir):
os.makedirs(self.output_dataset_dir)
self.img_file = os.listdir(self.dataset_dir)
print("[INFO] {} images found".format(len(self.img_file) - 1))
print("[INFO] ---- x | y | width | height ---- output format".format(len(self.img_file) - 1))
self.make_labels()
if self.names == '1':
self.make_names()
def run_dummy(self, dummy_name):
self.make_start()
dataset_dir = os.path.join(ROOT_DIR, 'Dataset', self.dataset, dummy_name)
self.output_dataset_dir = os.path.join(OUTPUT_DIR, NAME_DIR, self.dataset, self.class_name)
if not os.path.exists(self.output_dataset_dir):
print("The selected output folder does not exists")
exit(1)
img_file = os.listdir(dataset_dir)
print("[INFO] {} images found".format(len(img_file) - 1))
print("[INFO] VOID output format".format(len(img_file) - 1))
for element in tqdm(img_file):
if element.endswith('.jpg'):
img_path = os.path.join(dataset_dir, element)
self.img_path_yolo = os.path.join(self.output_dataset_dir, element)
img_name = str(element.split('.')[0]) + '.txt'
label_path_yolo = os.path.join(self.output_dataset_dir, img_name)
self.img = cv2.imread(img_path)
label_yolo = open(label_path_yolo, 'w')
label_yolo.close()
if self.copy == '1':
self.make_copy()
if self.move == '1':
self.make_copy()
self.make_end()
def make_labels(self):
for element in tqdm(self.img_file):
if element.endswith('.jpg'):
self.img_path = os.path.join(self.dataset_dir, element)
self.img_path_yolo = os.path.join(self.output_dataset_dir, element)
img_name = str(element.split('.')[0]) + '.txt'
self.label_path_original = os.path.join(self.label_dir, img_name)
label_path_yolo = os.path.join(self.output_dataset_dir, img_name)
self.img = cv2.imread(self.img_path)
label_original = open(self.label_path_original, 'r')
label_yolo = open(label_path_yolo, 'w')
for line in label_original:
# name_of_class X_min Y_min X_max Y_max
line = line.strip()
l = line.split(' ')
class_name = l.pop(0)
try:
float(l[0])
except ValueError:
class_name += ' ' + l.pop(0)
if class_name not in self.class_list:
self.class_list.append(class_name)
for i in range(len(l)):
l[i] = float(l[i])
x = ((l[2] + l[0]) / 2)
y = ((l[3] + l[1]) / 2)
width = (l[2] - l[0])
height = (l[3] - l[1])
img_width = 1 / self.img.shape[1]
img_height = 1 / self.img.shape[0]
x *= img_width
y *= img_height
width *= img_width
height *= img_height
if self.class_number != 0:
c_name = self.class_number
else:
c_name = self.class_list.index(class_name)
print("{0} {1} {2} {3} {4}".format(c_name, x, y, width, height), file=label_yolo)
if self.copy == '1':
self.make_copy()
if self.move == '1':
self.make_copy()
self.make_move()
label_yolo.close()
label_original.close()
self.make_end()
def make_copy(self):
cv2.imwrite(self.img_path_yolo, self.img)
def make_move(self):
os.remove(self.img_path)
os.remove(self.label_path_original)
def make_names(self):
file_path = os.path.join(OUTPUT_DIR, NAME_DIR, 'obj.names')
f = open(file_path, 'w')
for i in range(len(self.class_list)):
print("{}".format((self.class_list[i]).lower()), file=f)
f.close()
def make_end(self):
if self.copy == '1':
print("[INFO] Done!")
print("[INFO] There are {} images in your dataset".format(len(os.listdir(self.output_dataset_dir)) / 2))
else:
print("[INFO] Done!")
print("[INFO] There are {} images in your dataset".format(len(os.listdir(self.output_dataset_dir))))
def make_start(self):
print(dedent("""
_____ ____ ____ _ _ __
( _ )(_ _)( _ \( \/ )/. |
)(_)( _)(_ )(_) )\ /(_ _)
(_____)(____)(____/ \/ (_)
____ _____
(_ _)( _ )
)( )(_)(
(__) (_____)
_ _ _____ __ _____
( \/ )( _ )( ) ( _ )
\ / )(_)( )(__ )(_)(
(__) (_____)(____)(_____)
"""))
if __name__ == '__main__':
args = argument_parser()
if args.command == 'convert':
converter = Engine(args.dataset, args.class_name, args.class_number, args.copy, args.names, args.move)
converter.run_converter()
if args.command == 'dummy':
dummy_generator = Engine(args.dataset, args.class_name, args.class_number, args.copy, args.names, args.move)
dummy_generator.run_dummy(args.dummy_name)
해당 파이썬 실행 파일의 파라미터의 경우 파일의
상단을 참고하시면 됩니다.
# OIDv4_ToolKit 위치로 이동
cd OIDv4_ToolKit
# oid_to_yolo.py 실행
python oid_to_yolo.py convert --dataset test --class_name Jellyfish --copy True해당 파일 실행 결과 정상적으로 OUTPUT 풀더 내에
복사 된 이미지 파일과 YOLO 형식으로 정규화 된 라벨 파일 104쌍이 완료 되었습니다.

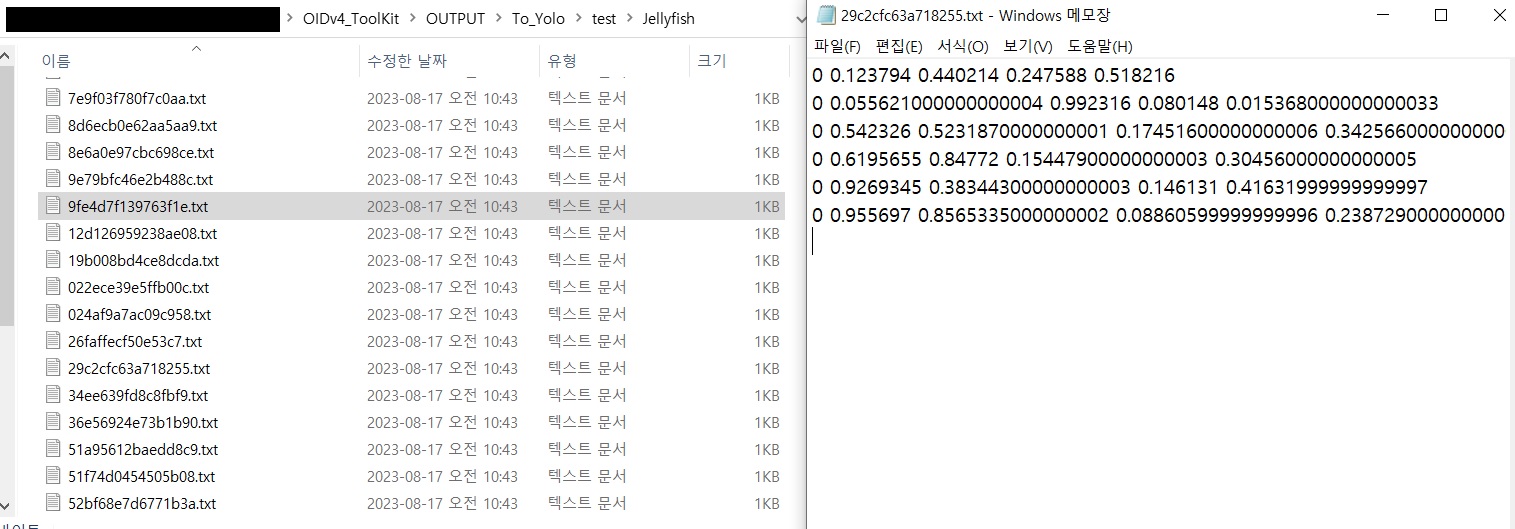
개인적으로는 OIDv4_ToolKit의 방식이 정규화도 간편하고
원하는 이미지 데이터셋만 얻을 수 있어 편리한 것 같습니다.